




Quand vient le temps de faire une nouvelle promotion ciblée, le réflexe de base est généralement de faire une offre à un client qui a la plus grande propension à acheter le produit/service. Celui qui a un intérêt déjà démontré. Par contre, quelle est l’efficacité d’une promotion faite à un client qui, en principe, aurait acheté le produit de toute façon? Et à l’inverse, quelle réaction peut avoir un client qui déteste être contacté?
La propension à acheter un produit/service seule n’est pas la seule information à tenir en compte. En poussant l’analyse prédictive un peu plus loin, on peut ajouter une dimension à cette propension, soit la probabilité d’acheter seulement s’il reçoit une offre. Ainsi, au lieu de cibler les clients qui auraient un intérêt de toute façon, on peut restreindre les offres à ceux qui, sans l’incitatif, n’auraient pas acheté le produit. On peut également identifier ceux qui pourraient avoir une réaction négative face à la sollicitation. On peut penser ici à la sollicitation en reciblage publicitaire par exemple (remarketing), qui ferait en sorte d’amener le client à quitter.
Plus spécifiquement, on classifie les clients dans l’un des 4 cadrans suivants, selon leur propension à acheter avec et sans sollicitation.
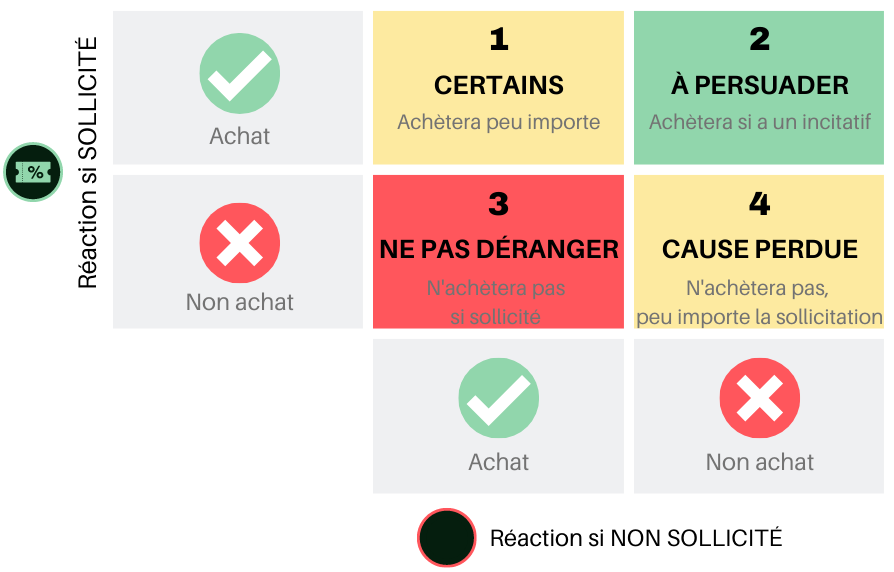
Avec ce modèle, on cherche à identifier les clients qui seront les plus enclins à réagir à une offre promotionnelle.
Les bénéfices :
Ainsi, on accroît les ventes incrémentales, on diminue les coûts et donc, on voit une amélioration du ROI.
L’uplift se définit comme l’incrément sur l’achat généré par l’offre, par rapport au fait de n’avoir posé aucune action.
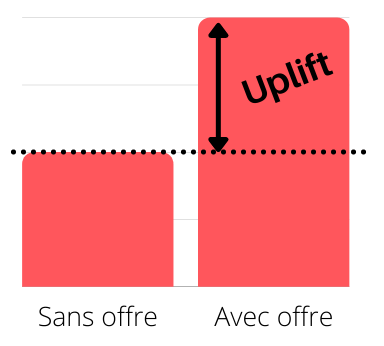
L’enjeu méthodologique vient du fait qu’une personne ne peut pas simultanément avoir reçu et ne pas avoir reçu l’offre, donc impossible d’observer l’uplift au niveau individuel. Et donc, difficile d’identifier les individus pour lesquels cette action a eu une influence sur leur comportement. Difficile oui, mais pas impossible!
Une première approche, à la fois directe et intuitive, utilise deux modèles (logistiques, par exemple): On commence par assigner aléatoirement chaque individu soit au groupe des ciblés, recevant l’offre, soit au groupe contrôle, ne la recevant pas. Un premier modèle utilise le groupe des ciblés pour prédire l’achat sachant qu’une offre a été reçue, tandis qu’un second modèle utilise le groupe contrôle pour prédire l’achat sans offre.
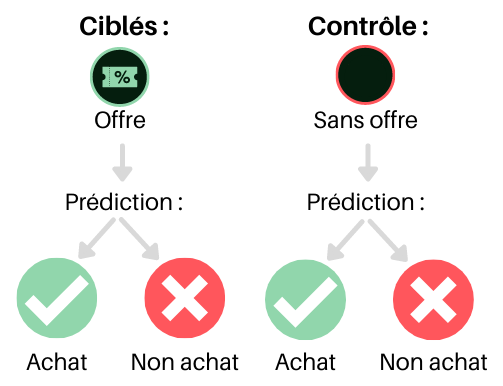
Une fois ces modèles bâtis, on peut estimer la propension à acheter de n’importe quel individu dans les deux situations, peu importe qu’il ait reçu ou non l’offre en réalité. Les individus qui auront une forte propension à acheter s’ils reçoivent l’offre, mais une faible propension s’ils ne la reçoivent pas seront les plus avantageux à solliciter (la classe « à persuader »).
Bien que cette méthode soit plus liée au but de l’analyse que les modèles prédisant l’achat peu importe l’offre reçue, elle n’est pas la plus performante pour répondre à la question d’intérêt. En effet, chacun des deux modèles étant optimisé selon sa capacité à prédire l’achat, rien de garanti que la combinaison des deux soit optimisée pour prédire la différence de propension à acheter entre les deux groupes.
Une approche préférable consiste à employer des arbres de décisions basés sur l’uplift. Les arbres des décisions classiques utilisent les caractéristiques des individus (socio-démographiques, transactionnelles, etc.) pour séparer successivement l’échantillon selon les coupures qui entraînent les plus grandes différences dans la propension à l’achat. L’arbre basé sur l’uplift, quant à lui, effectue ses coupures de sorte à maximiser la différence d’uplift entre les deux sous-groupes ainsi créés, tout en évitant de créer des sous-groupes de trop petite taille pour être pertinents.
Par exemple, on pourrait constater que chez les moins de 35 ans, les consommateurs sollicités avec une offre courriel achètent deux fois moins que les personnes non-sollicitées, tandis que chez les 35 ans et plus, les personnes sollicitées achètent trois fois plus que celles n’ayant pas été sollicitées. On viendrait donc d’identifier que les moins de 35 ans appartiennent à la classe « à ne pas déranger », l’offre ayant en moyenne un effet négatif chez eux. Évidemment, dans un contexte d’affaires, rares sont les cas où un seul facteur a autant d’impact. Le processus itératif se poursuit donc en utilisant l’ensemble des caractéristiques connues des individus de sorte à créer une série de groupes, ou segments, qui se distinguent sur leur propension à acheter.
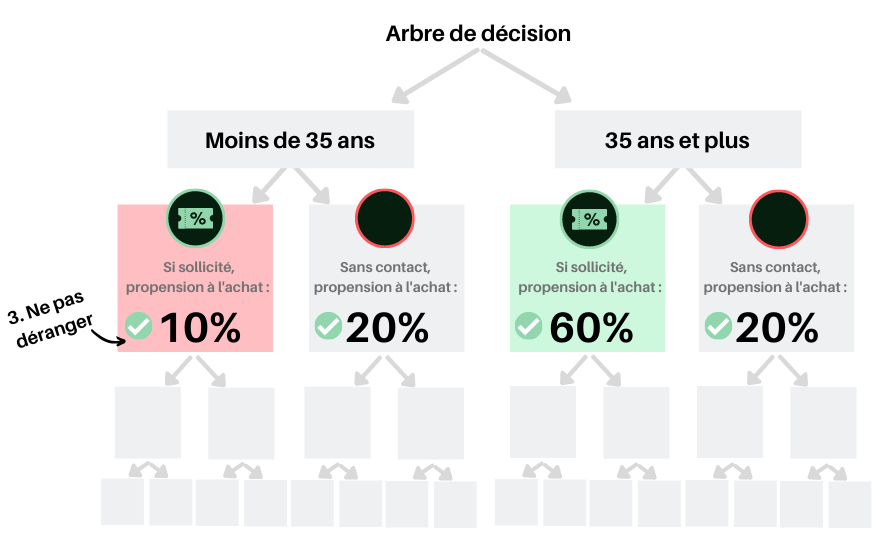
Une fois l’arbre créé, pour tout individu, on peut identifier à quel segment il appartient en se basant sur ses caractéristiques et estimer l’impact de l’offre sur celui-ci à l’aide de l’uplift observé dans ce segment (la propension d’achat parmi ceux ayant reçu l’offre comparée à celle parmi les gens ne l’ayant pas reçu).
Le modèle Uplift peut être un outil fort utile en fidélisation pour améliorer le résultat des campagnes marketing. On peut également combiner une variété de contacts du parcours client pour en améliorer l’efficacité.
Envie d’en savoir plus? Nos experts peuvent vous aider.
Références
Radcliffe, N., & Surry, P. (2012). Real-World Uplift Modelling with Significance-Based Uplift Trees, https://www.stochasticsolutions.com/pdf/sig-based-up-trees.pdf