




When it comes time to launch a new targeted promotion, the basic instinct is usually to make an offer to a customer who has the greatest propensity to purchase the product/service. One who has already demonstrated an interest. However, how effective is a promotion to a customer who, in principle, would have bought the product anyway? And conversely, what reaction can a customer who hates being contacted have?
The propensity to buy a product/service alone is not the only information to consider. By pushing predictive analytics a step further, we can add a dimension to this propensity, namely the probability of buying only if they receive an offer. So instead of targeting customers who would have an interest anyway, you can restrict the offers to those who, without the incentive, would not have purchased the product. We can also identify those who might have a negative reaction to the solicitation. We can think of the solicitation as being behavioural retargeting for example (remarketing), which would cause the customer to leave.
More specifically, customers are classified into one of the following 4 quadrants, according to their propensity to buy with and without solicitation.

With this model, we try to identify the customers who will be the most inclined to react to a promotional offer.
Benefits:
Thus, we increase incremental sales, we reduce costs and therefore, we see an improvement in ROI.
The uplift is defined as the incremental purchase generated by the offer, compared to not having taken any action.
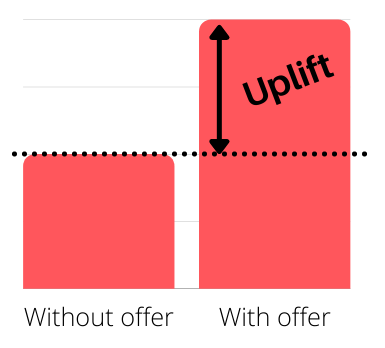
The methodological issue arises from the fact that a person cannot simultaneously have received and not received the offer, therefore it is impossible to observe the uplift at the individual level. Therefore, it is difficult to identify the individuals for whom this action had an influence on their behavior. Difficult, yes, but not impossible!
A first approach, both direct and intuitive, uses two models (logistics, for example): We start by randomly assigning each individual either to the target group, receiving the offer, or to the control group, not receiving it. A first model uses the target group to predict the purchase knowing that an offer has been received, while a second model uses the control group to predict the purchase without an offer.
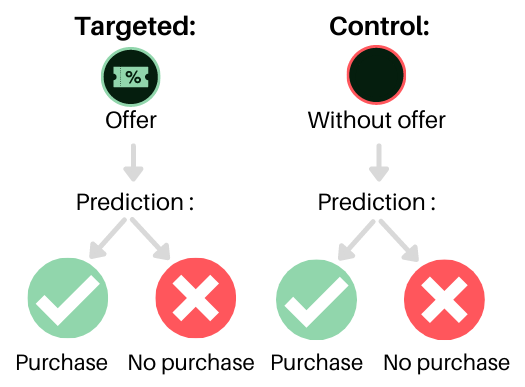
Once these models are built, we can estimate the propensity to buy of any individual in both situations, regardless of whether they received the offer. Individuals who will have a high propensity to buy if they receive the offer, but a low propensity if they do not receive it will be the most beneficial to solicit (the “persuade” class).
Although this method is more related to the purpose of the analysis than models predicting the purchase regardless of the offer received, it is not the most efficient at answering the question of interest. Indeed, each of the two models being optimized according to its ability to predict buying, there is no guarantee that the combination of the two will be optimized to predict the difference in propensity to buy between the two groups.
A preferable approach is to use uplift-based decision trees. Classic decision trees use the characteristics of individuals (socio-demographic, transactional, etc.) to successively separate the sample according to the segments that cause the greatest differences in the propensity to buy. The tree based on the uplift, on the other hand, segments to maximize the difference in uplift between the two sub-groups thus created, while avoiding creating sub-groups that are too small to be relevant.
For example, we could see that among those under 35, those who have been called buy half as much as unsolicited people, while among those aged 35 and over, those who were called buy three times more than those who do not receive a call. We would therefore come to identify that those under 35 belong to the “do not disturb” class, with the offer having a negative effect on them on average. Obviously, in a business context, rare are the cases in which a single factor would have so much impact. The iterative process therefore continues by using all the characteristics known to individuals to create a series of groups, or segments, which differ in their propensity to buy.
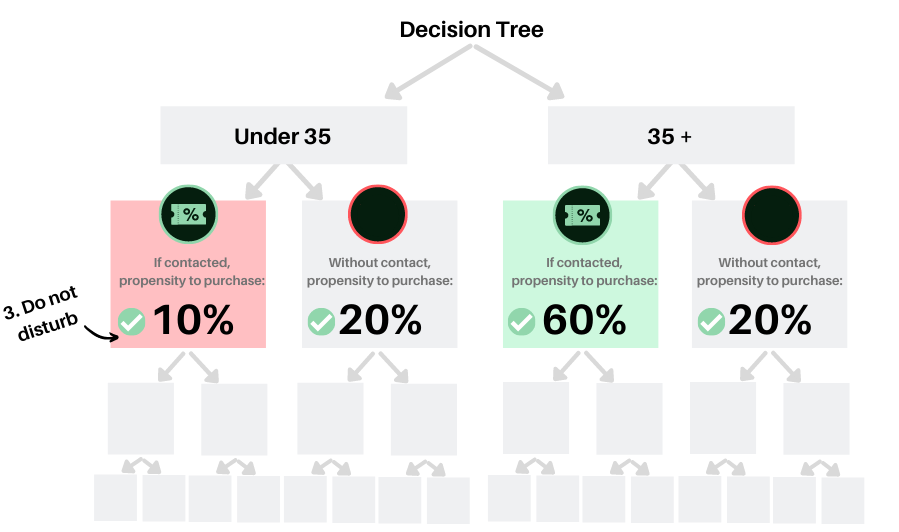
Once the tree has been created, for any individual, we can identify which segment they belong to based on their characteristics and estimate the impact of the offer on them using the uplift observed in this segment (the propensity to buy among those who received the offer compared to the people who did not receive it).
The uplift model can be a very useful loyalty tool to improve the results of marketing campaigns. You can also combine a variety of customer journey contacts to improve efficiency.
Want to know more? Our experts can help you.
References
Radcliffe, N., & Surry, P. (2012). Real-World Uplift Modelling with Significance-Based Uplift Trees, https://www.stochasticsolutions.com/pdf/sig-based-up-trees.pdf